�������Ҋ(ji��n)�����S��(y��u)��������Փ�о��ܶ࣬���ڌ�(sh��)�H��(y��ng)���Л](m��i)��һ�N�܉�ص����������`������`��Ĵ��ڣ�ʹ��(sh��)�H��(y��ng)�����������F(xi��n)�@�N��r����ԭʼ���ϵĔ�(sh��)��(j��)��С��׃���Y(ji��)����(hu��)���ͬ����������ijһ�yֵ���Ӹ�׃����(y��u)���Y(ji��)����(hu��)�ܴ�׃����������Ӌ(j��)��C(j��)�`��̎���ľ��ȸ�׃���Y(ji��)��Ҳ��(hu��)�l(f��)��һ��׃����һ��(g��)��(y��u)��������܌�(du��)ijһ�M��(sh��)��(j��)Ч������(du��)�ܺã���(du��)����һ�M��(sh��)��(j��)Ч������(du��)��������ȵȡ��@Щ�����Ƀ�(y��u)�����ϱ����ď�(f��)�s�Ժ��㷨�������Q���ģ�ܛ����(sh��)�F(xi��n)�еą���(sh��)�����ӵȔ�(sh��)ֵ���O(sh��)��ֻ�ܱ��C��һ��(g��)���õĔ�(sh��)�W(xu��)����ֵ���s���y����(j��)ԭʼ��(sh��)��(j��)�����ϼs�������(l��i)�a(ch��n)��һ��(g��)��ѵ�ֵ�����ͨ�^(gu��)����(d��ng)׃���ą���(sh��)�����Ӂ�(l��i)����O(sh��)����ֵ���Ϳ��ܵõ�����(y��u)�ă�(y��u)���Y(ji��)��������Ȼ����Ӌ(j��)��r(sh��)�g�Ĵ����_(k��i)�N���@�NӋ(j��)��r(sh��)�g�Еr(sh��)�������Ñ����������̵ġ�
2 �µă�(y��u)��̎��ģ��
�����φ�(w��n)�}�������Կ��������y����һ�Nܛ����ʹ֮�M����N���Ϸ�ʽ�����ϔ�(sh��)��(j��)�����Ñ�(sh��)�H��(y��ng)���^(gu��)���У�������r�͔�(sh��)��(j��)ǧ׃?n��i)f������(du��)��ijһ��(g��)ܛ���Ñ�����(y��ng)��һ�Nܛ����������ij�N��r����Ч���ã�����Щ��r�¿�������Ч���Ͳ��Ǻ����롣����(du��)ÿһ�����ϣ�����ֱ��Ӱ��Ñ��Ĺ��̳ɱ����YԴ�������ʣ�����о�һ�N�ڸ��N��r�¾��ܵõ��M�����ϽY(ji��)�������Ϸ������зdz���Ҫ�ĬF(xi��n)��(sh��)���x��
��ͬ�㷨����ͬ�㷨����(sh��)��ͬ�����܌�(du��)һЩ��(sh��)��(j��)��Ч����ͬ����Ŀǰ���y�Ĕ�(sh��)�W(xu��)�㷨��ܛ���O(sh��)Ӌ(j��)�Ϗص�Q�@��(g��)��(w��n)�}�����y�о���һ�N�ڸ��N��r��(y��u)��Ч�����ܺõđ�(y��ng)��ܛ�������о��И�(g��u)���ˈD1��ʾ�ă�(y��u)��̎��ģ�͡��ڈD1�ă�(y��u)��̎��ģ���У���(y��u)��ܛ�������Dz�ͬ�����㷨���Ƶ�ܛ����Ҳ��������ͬ�����㷨����(sh��)�{(di��o)�����γɵ�ܛ����ǰ̎��ģ�K�nj����N�y(t��ng)һ��(sh��)��(j��)��ʽ�����ϔ�(sh��)��(j��)�D(zhu��n)����ij�N��(y��u)��ܛ�����õĔ�(sh��)��(j��)��ʽ����̎��ģ�K�nj����N��ʽ�ĽY(ji��)����(sh��)��(j��)�D(zhu��n)����y(t��ng)һ��ݔ����ʽ���Y(ji��)���u(p��ng)��ؓ(f��)؟(z��)������(g��)��(y��ng)�ó���ă�(y��u)���Y(ji��)���M(j��n)�б��^���ó�һ��(g��)�(y��u)�ĽY(ji��)����
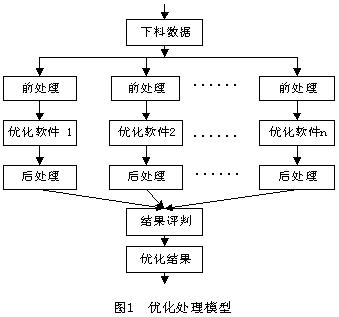
�ɈD1ģ�Ϳ��Կ�����ԓģ�Ͳ����Ǐă�(y��u)���㷨���M(j��n)���о�������һ�N���ɮ�(d��ng)ǰ��(y��u)������ܛ�����о��ɹ��ķ�������(du��)��һ�M���ϔ�(sh��)��(j��)�����Ⱥ��y֪������Щܛ���ܵõ��^��(y��u)�����ϽY(ji��)������ͨ�^(gu��)����(g��)ܛ���IJ��Ѓ�(y��u)�����ϣ�����x��һ��(g��)����(du��)�(y��u)�ĽY(ji��)�����،��M(j��n)һ����߃�(y��u)�����ϵĿ��wЧ����ģ�;������õĔU(ku��)��������������Գ�ָ��S���N��(y��u)���о������³ɹ�����(d��ng)�B(t��i)�{(di��o)����(y��u)��ܛ�����l(f��)�]���N��(y��u)��ܛ���ă�(y��u)��(sh��)�����_(d��)���m�˶�N���Ϸ�ʽ�͌�(du��)���N��(sh��)��(j��)�����НM��ă�(y��u)�������ʵ�Ŀ�ġ�ģ������߃�(y��u)�������ʵ�ͬ�r(sh��)�����ڸ���(y��u)��ܛ�����Էֲ��ڲ�ͬ�ęC(j��)�����Ɍ�(sh��)�F(xi��n)���Ѓ�(y��u)�����p�����ϕr(sh��)�g��
3 ����Internet�ķ������䌍(sh��)�F(xi��n)
�D1�еă�(y��u)��̎��ģ�ͣ�����ͬ�r(sh��)��Q��N��(y��u)����ʽ����(y��u)�������ʺ����ϕr(sh��)�g�Ć�(w��n)�}������(du��)��һ��(g��)���w�Ñ���Ҫ��(g��u)���@��(g��)ģ���Ƿdz����y�ġ�һ�����N��(y��u)��ܛ����ُ(g��u)�I�����νӿ��_(k��i)�l(f��)�����M(f��i)������������������ؔ(c��i)������һ���昋(g��u)��ԓģ����Ҫ������Ӌ(j��)��C(j��)
�O(sh��)������(du��)��һ��(g��)�ض��Ñ�����(g��u)����ģ���@Ȼ�Dz��F(xi��n)��(sh��)�ġ���ģ��Ҫ�l(f��)�]Ч�������]һ�N�Ќ�(sh��)���еđ�(y��ng)�÷�ʽ�Ƿdz���Ҫ�ġ�
�����(l��i)��Internet���g(sh��)�õ����w�ٵİl(f��)չ���S��Ӌ(j��)��C(j��)ܛ���_(k��i)�l(f��)�̞�����߮a(ch��n)Ʒ���ܡ�����a(ch��n)Ʒ�S�o(h��)������(j��)���u�u���a(ch��n)Ʒ�D(zhu��n)׃?y��u)�ͨ�^(gu��)Internet�ṩ����(w��)���˂�Ҳ�u�u��(x��)�Tܛ�����ú����û�(li��n)�W(w��ng)��(l��i)�ṩ����(w��)��˼�롣�҂�����ǰ������ă�(y��u)��̎��ģ�ͽY(ji��)��Internet���g(sh��)�������һ�N����Internet�Ķ��S��(y��u)�����Ϸ��������w��(sh��)�F(xi��n)���g(sh��)��D2���D2���J(r��n)�C����ؓ(f��)؟(z��)��(du��)�Ñ��M(j��n)�������(y��n)�C��������Ч�Ñ��΄�(w��)�ύ�o�{(di��o)�����ģ��{(di��o)�����ĸ���(j��)�΄�(w��)��͡��΄�(w��)Ҫ����ɕr(sh��)�g������(y��u)��ܛ�����ܺ̓�(y��u)��ܛ���΄�(w��)��r���M(j��n)���΄�(w��)�{(di��o)�Ⱥͷְl(f��)���u(p��ng)�����Č���̎��C(j��)�õ��ă�(y��u)���Y(ji��)���M(j��n)�б��^�������(y��u)�Y(ji��)�������o�Ñ�����(y��u)��̎��C(j��)�ϰ��b���N��(y��u)��ܛ�����@Щ��(y��u)��ܛ���������ò�ͬ���㷨��(sh��)�F(xi��n)��Ҳ������ͬһ�㷨ܛ����(sh��)�F(xi��n)�в��õą���(sh��)��һ�ӡ����딵(sh��)��(j��)��(k��)�ϴ���Ñ���(sh��)��(j��)����(y��u)��̎�픵(sh��)��(j��)�����Ѓ�(y��u)��̎�픵(sh��)��(j��)��(j��ng)�^(gu��)һ���r(sh��)�g�đ�(y��ng)���۷e���������M(j��n)���㷨�о��͌�(du��)��(y��u)��̎��C(j��)�ϵ�ܛ�������M(j��n)���u(p��ng)�r(ji��)��
 ��һ�(y��)123��һ�(y��)
��һ�(y��)123��һ�(y��)




















